阿里云PolarDB及其共享存儲PolarFS技術實現分析(上) 數據處理與存儲支持服務
隨著云計算和大數據時代的深入發展,企業對數據庫的性能、擴展性、可靠性和成本效益提出了前所未有的高要求。傳統數據庫架構,尤其是基于本地存儲的共享存儲架構,在應對海量數據、高并發訪問及彈性伸縮需求時,常常面臨瓶頸。阿里云推出的云原生數據庫PolarDB,通過創新的“計算與存儲分離”架構和自研的分布式共享存儲系統PolarFS,為這些挑戰提供了優雅的解決方案。本文上篇將聚焦于PolarDB的整體數據處理流程及其底層核心——存儲支持服務PolarFS的實現機制。
一、PolarDB概述:云原生數據庫的架構革新
PolarDB是阿里云自主研發的云原生關系型數據庫,100%兼容MySQL、PostgreSQL和Oracle引擎。其最核心的創新在于采用了“計算與存儲分離”的架構。在此架構下:
- 計算層(數據庫引擎節點):由多個讀寫節點(RW)和只讀節點(RO)組成,它們是無狀態的,主要負責SQL解析、優化、執行、事務處理等計算任務。計算節點可以根據業務負載動態彈性擴縮容。
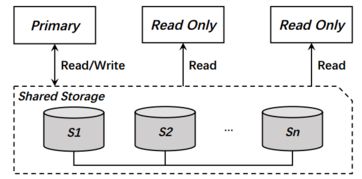
- 存儲層:由一個跨多個物理服務器的、高性能的分布式共享存儲集群構成。所有計算節點都通過高速網絡(如RDMA)訪問同一份存儲數據,實現了數據的強一致性和共享。
- 日志即數據(Log is Data):PolarDB摒棄了傳統數據庫中將數據頁(Page)作為同步單元的模式,轉而將重做日志(Redo Log)作為主同步介質。存儲層直接接收并持久化來自主節點的Redo Log,并在后臺異步地將其應用(回放)到數據頁上。這極大地減少了主節點與存儲層之間、以及主從節點之間的數據傳輸量,降低了主節點的寫延遲和負載。
這種分離架構帶來了顯著優勢:存儲容量可獨立、無縫擴展至百TB級別;計算節點快速彈性伸縮(分鐘級增加只讀實例);存儲按實際使用量計費,成本更低;并通過多副本機制保障了數據的高可靠性與高可用性。
二、數據處理流程:從SQL到持久化存儲
在PolarDB中,一條寫事務(如INSERT/UPDATE)的生命周期清晰地體現了其架構優勢:
- SQL處理:主計算節點接收SQL請求,經過解析、優化后,在內存中執行數據修改,生成對應的Redo Log記錄(描述數據的變化,而非數據頁本身)。
- 日志下沉(Log Sink):主節點不是將修改后的臟數據頁刷盤,而是將生成的Redo Log通過高效網絡協議批量、并行地發送到后端的PolarFS存儲集群。這個過程是同步的,確保日志持久化后事務才算提交成功,保證了持久性(Durability)。
- 存儲層持久化與應用:PolarFS接收Redo Log,首先將其持久化寫入到多副本的日志存儲系統中。存儲層內部的“日志回放服務”會異步地將這些Redo Log應用到對應的數據頁上,生成新的數據頁版本。數據頁以“寫時復制(Copy-on-Write)”方式更新,舊版本得以保留,這天然支持了快速快照功能,是備份、克隆等操作的基礎。
- 只讀節點數據同步:只讀節點(RO)不與存儲層進行復雜的數據頁同步。它們只需從存儲層(或主節點)獲取最新的Redo Log,并在本地內存中回放,即可獲得與主節點一致的數據視圖。這避免了從主節點復制大量數據頁帶來的網絡和I/O開銷,使得只讀節點的添加幾乎不影響主節點性能,實現了近乎線性的擴展。
三、核心基石:PolarFS分布式共享存儲系統
PolarFS是支撐PolarDB“計算與存儲分離”架構的自研高性能分布式文件系統,它是整個系統的數據持久化基石。其設計目標是為數據庫負載提供極低延遲、高吞吐、強一致和高可用的塊存儲服務。
1. 架構設計
PolarFS采用分層架構:
- 客戶端(ChunkServer Client):嵌入在每個數據庫計算節點中,以用戶態文件系統(FUSE)或內核模塊形式存在,提供標準的POSIX文件接口(如pwrite/pread)。它負責處理I/O請求的路由、緩存和協議編解碼。
- 元數據服務(ChunkMaster):管理整個文件系統的命名空間、文件到數據塊(Chunk)的映射關系、以及數據塊副本的位置信息。它本身是高可用的集群。
- 數據存儲服務(ChunkServer):負責實際數據塊(通常為幾十MB大小)的存儲。數據塊以多副本(通常為3副本)形式分布在不同的物理服務器上,通過Raft共識協議保證副本間的一致性。
2. 關鍵技術創新
為了實現數據庫所需的極致I/O性能,PolarFS集成了多項尖端技術:
- RDMA高速網絡:計算節點與存儲節點之間、存儲節點內部廣泛使用RDMA(遠程直接內存訪問)技術進行通信。RDMA允許數據繞過操作系統內核和CPU,直接從一臺機器的內存傳輸到另一臺機器的內存,大幅降低了網絡延遲和CPU開銷。這是實現低延遲同步寫日志的關鍵。
- 用戶態I/O棧(Bypass Kernel):傳統的文件系統I/O路徑需要經過內核,存在上下文切換和內存拷貝的開銷。PolarFS的客戶端運行在用戶態,通過SPDK(存儲性能開發工具包)等技術直接訪問NVMe SSD等硬件,實現了從應用到存儲介質的“零拷貝”短路徑,顯著提升I/O效率。
- 并行復制與一致性協議優化:針對數據庫寫日志的順序、小塊、高并發特點,PolarFS優化了數據復制流程。它支持將小I/O合并后并行復制到多個副本,并利用RDMA進行流水線式傳輸,在保證強一致性的前提下,最大化寫吞吐量。
- 智能I/O調度與本地性感知:PolarFS能夠感知數據塊的分布,并智能地將I/O請求路由到最近的或負載最輕的副本。對于讀請求,尤其是只讀節點的讀,可以優先從本地或同可用區的副本讀取,減少網絡延遲。
小結
阿里云PolarDB通過將“計算與存儲分離”與“日志即數據”理念深度融合,重構了云數據庫的架構范式。其上半部分——數據處理流程,高效地將數據庫計算與持久化存儲解耦;而下半部分——由PolarFS提供的共享存儲支持服務,則通過RDMA、用戶態I/O棧等前沿技術,為上述架構提供了堅實、高性能、彈性的存儲底盤。正是這兩者的協同創新,使得PolarDB能夠在提供企業級功能與兼容性的在彈性、擴展性、性價比上獲得突破性進展。在下篇中,我們將進一步深入分析PolarDB在高可用、彈性擴展、備份恢復等高級功能上的具體技術實現。
如若轉載,請注明出處:http://www.namiko.cn/product/50.html
更新時間:2026-01-08 15:05:38